1/1
Are AI Benchmarks Trustworthy?
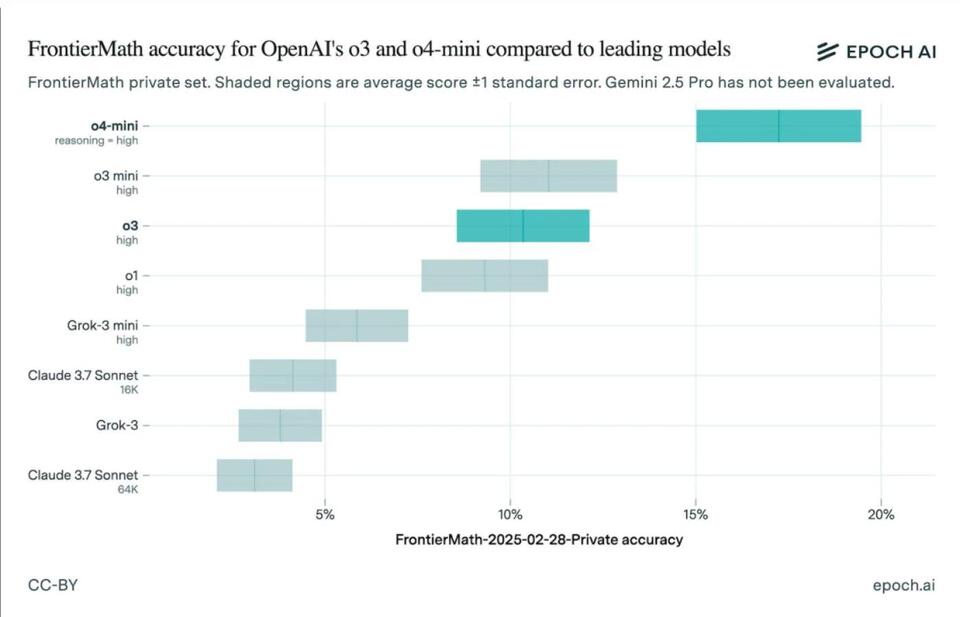
OpenAI’s o3 model just got called out for not living up to its math skills hype. The latest FrontierMath results show it scored much lower than OpenAI first claimed. With benchmarks shifting and models evolving fast, how much should we trust these numbers? Are we putting too much faith in test results that might not tell the whole story? Let’s dig in—do benchmarks help or hurt real AI progress? #AIethics #OpenAI #FrontierMath #TechDebate #AIBenchmarks #Tech
2025-04-23
write a comment...